|
I am a fourth-year PhD student at Columbia University advised by Carl Vondrick and Richard Zemel. My work is supported by the NSF Graduate Research Fellowship. Previously, I completed my B.S. in Computer Science at Georgia Tech where I worked on Algorithmic Fairness advised by Judy Hoffman I have had the opportunity to intern at Microsoft Research (2022) with Vibhav Vineet and Neel Joshi. I have spent 3 summers working as a Software Engineering Intern with Bloomberg and Microsoft. I am also an active mobile app development volunteer for YogaSangeeta. In my free time, I enjoy classical indian dancing and spending time with friends and family. Feel free to email me to chat about research, grad school applications, or life! |

|
|
I'm interested in enabling agents to build representations of their environment and act in the world by learning from offline data and real-world interactions. Building such systems raises many facinating learning questions that I am interested in exploring including perception, generalization, compositionality, and explainability. |
|
Junban Liang, Ege Ozguroglu, Ruoshi Liu, Sruthi Sudhakar, Achal Dave, Pavel Tokmakov, Shuran Song, Carl Vondrick, Conference on Robot Learning 2024 arXiv Dreamitate is a visuomotor policy learning framework that synthesize videos of humans using tools to complete a task, tracks the tool, and executes the trajectory on the robot to accomplish the task in the real-world. |
|
|
Ruoshi Liu, Junban Liang, Sruthi Sudhakar, Huy Ha, Cheng Chi, Shuran Song, Carl Vondrick arxiv project page, arXiv PaperBot directly learns to design and use a tool in the real world using paper without human intervention. |
|
|
Sruthi Sudhakar, Ruoshi Liu, Basile Van Hoorick, Carl Vondrick, Richard Zemel, ECCV 2024 (Oral, Best Paper Award Candidate) project page, arXiv We propose learning to model interactions through a novel form of visual conditioning: hands. Hands are a natural way to specify control through actions such as grasping, pulling, pushing, etc. Given an input image and a representation of a hand interacting with the scene, our approach, CoSHAND, synthesizes a depiction of what the scene would look like after the interaction has occurred. |
|
 
|
Sruthi Sudhakar, Jon Hanzelka, Josh Bobillot, Tanmay Randhavane, Neel Joshi, Vibhav Vineet, ICCV 2023 arXiv We study factors of variation in 3D model quality between simulated and real data to determine what factors are important for computer vision model performanc. To do so, we create a new YCB-Real and digital twin YCB-Synthetic dataset to study adaptation and generalization in controlled environments. |
|
|
Sruthi Sudhakar, Viraj Prabhu, Olga Russakovsky, Judy Hoffman, CVPR SSAD Workshop 2023 arXiv ICON2 leverages prior knowledge on the deficiencies of object detection systems to identify performance discrepancies across sub-populations, compute correlations between these potential confounders and a given sensitive attribute, and control for the most likely confounders to obtain a more reliable estimate of model bias. |
|
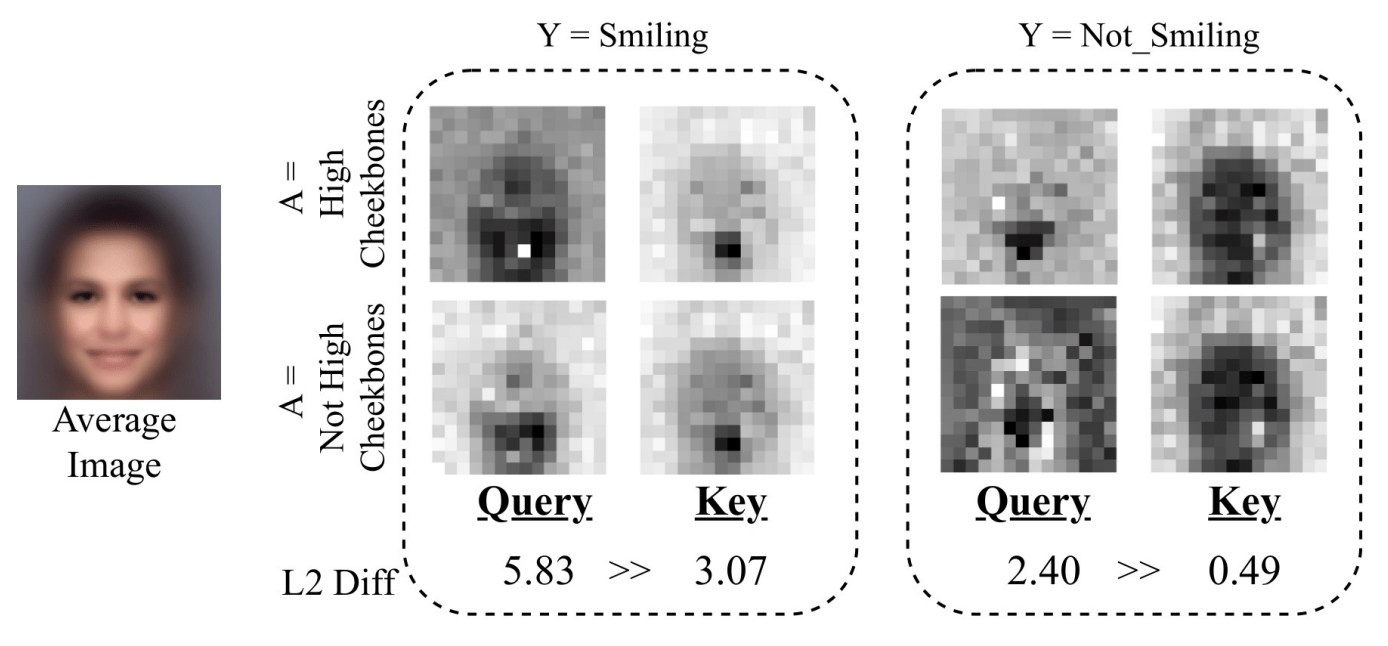
Sruthi Sudhakar, Aravind Krishnakumar, Viraj Prabhu, Judy Hoffman, BMVC 2021 arXiv TADeT: A targeted alignment strategy for debiasing transformers that aims to discover and remove bias primarily from query matrix features. |
|
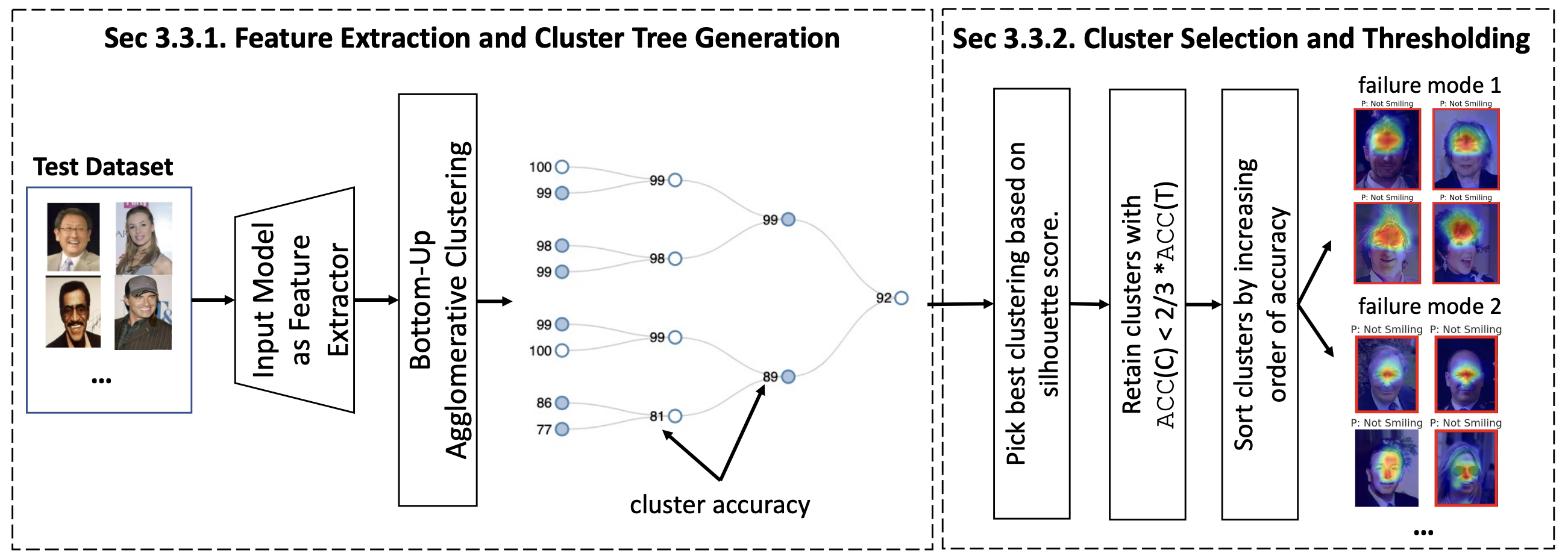
Aravind Krishnakumar, Sruthi Sudhakar, Viraj Prabhu, Judy Hoffman, BMVC 2021 arXiv UDIS identifies subpopulations via hierarchical clustering of dataset embeddings and surfaces systematic failure modes by visualizing low performing clusters along with their gradient-weighted class-activation maps. |
|
TA, Representation Learning with Prof. Carl Vondrick, Columbia University TA, Computer Vision with Prof. Judy Hoffman , Georgia Tech |
|
Website Credit, Jon Barron. |